 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGAR: Retrieval Augment Personalized Image Generation Guided by Recommendation
May 03, 2025Personalized image generation is crucial for improving the user experience, as it renders reference images into preferred ones according to user visual preferences. Although effective, existing methods face two main issues. First, existing methods treat all items in the user historical sequence equally when extracting user preferences, overlooking the varying semantic similarities between historical items and the reference item. Disproportionately high weights for low-similarity items distort users' visual preferences for the reference item. Second, existing methods heavily rely on consistency between generated and reference images to optimize the generation, which leads to underfitting user preferences and hinders personalization. To address these issues, we propose Retrieval Augment Personalized Image GenerAtion guided by Recommendation (RAGAR). Our approach uses a retrieval mechanism to assign different weights to historical items according to their similarities to the reference item, thereby extracting more refined users' visual preferences for the reference item. Then we introduce a novel rank task based on the multi-modal ranking model to optimize the personalization of the generated images instead of forcing depend on consistency. Extensive experiments and human evaluations on three real-world datasets demonstrate that RAGAR achieves significant improvements in both personalization and semantic metrics compared to five baselines.
Spatial Covariance Matrix Reconstruction for DOA Estimation in Hybrid Massive MIMO Systems with Multiple Radio Frequency Chains
Jun 20, 2021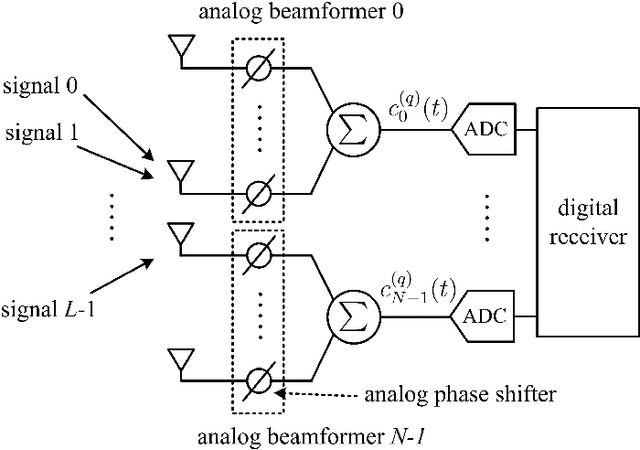
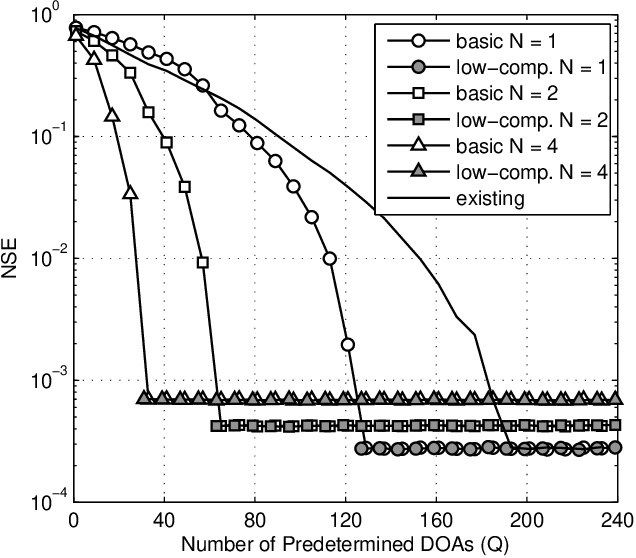
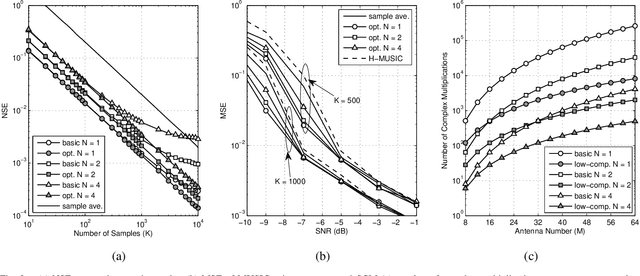
Multiple signal classification (MUSIC) has been widely applied in multiple-input multiple-output (MIMO) receivers for direction-of-arrival (DOA) estimation. To reduce the cost of radio frequency (RF) chains operating at millimeter-wave bands, hybrid analog-digital structure has been adopted in massive MIMO transceivers. In this situation, the received signals at the antennas are unavailable to the digital receiver, and as a consequence, the spatial covariance matrix (SCM), which is essential in MUSIC algorithm, cannot be obtained using traditional sample average approach. Based on our previous work, we propose a novel algorithm for SCM reconstruction in hybrid massive MIMO systems with multiple RF chains. By switching the analog beamformers to a group of predetermined DOAs, SCM can be reconstructed through the solutions of a set of linear equations. In addition, based on insightful analysis on that linear equations, a low-complexity algorithm, as well as a careful selection of the predetermined DOAs, will be also presented in this paper. Simulation results show that the proposed algorithms can reconstruct the SCM accurately so that MUSIC algorithm can be well used for DOA estimation in hybrid massive MIMO systems with multiple RF chains.
Self-Ensembling Contrastive Learning for Semi-Supervised Medical Image Segmentation
Jun 10, 2021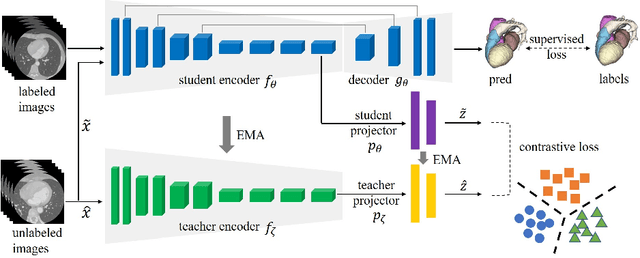
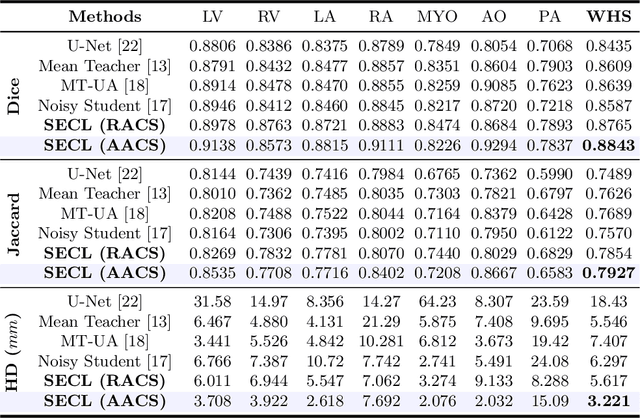
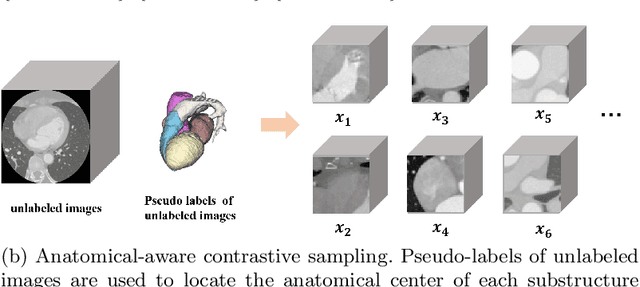
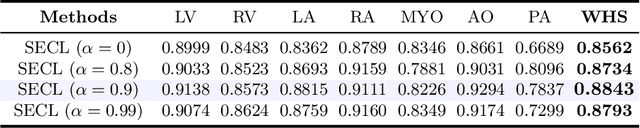
Deep learning has demonstrated significant improvements in medical image segmentation using a sufficiently large amount of training data with manual labels. Acquiring well-representative labels requires expert knowledge and exhaustive labors. In this paper, we aim to boost the performance of semi-supervised learning for medical image segmentation with limited labels using a self-ensembling contrastive learning technique. To this end, we propose to train an encoder-decoder network at image-level with small amounts of labeled images, and more importantly, we learn latent representations directly at feature-level by imposing contrastive loss on unlabeled images. This method strengthens intra-class compactness and inter-class separability, so as to get a better pixel classifier. Moreover, we devise a student encoder for online learning and an exponential moving average version of it, called teacher encoder, to improve the performance iteratively in a self-ensembling manner. To construct contrastive samples with unlabeled images, two sampling strategies that exploit structure similarity across medical images and utilize pseudo-labels for construction, termed region-aware and anatomical-aware contrastive sampling, are investigated. We conduct extensive experiments on an MRI and a CT segmentation dataset and demonstrate that in a limited label setting, the proposed method achieves state-of-the-art performance. Moreover, the anatomical-aware strategy that prepares contrastive samples on-the-fly using pseudo-labels realizes better contrastive regularization on feature representations.
An Empirical Study of Propagation-based Methods for Video Object Segmentation
Jul 30, 2019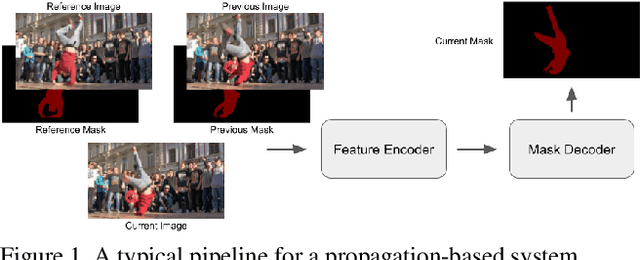
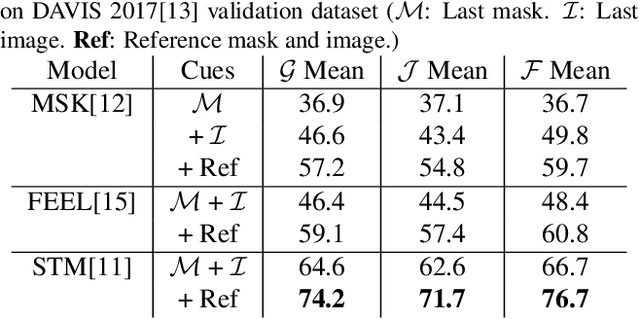
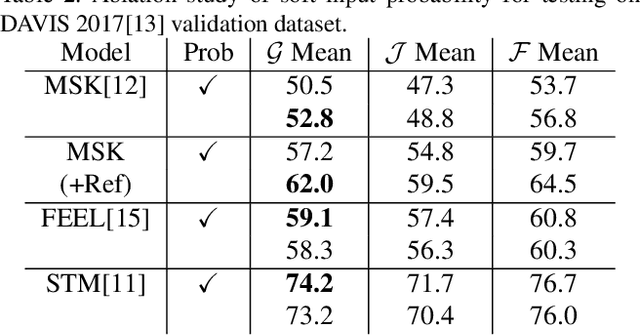
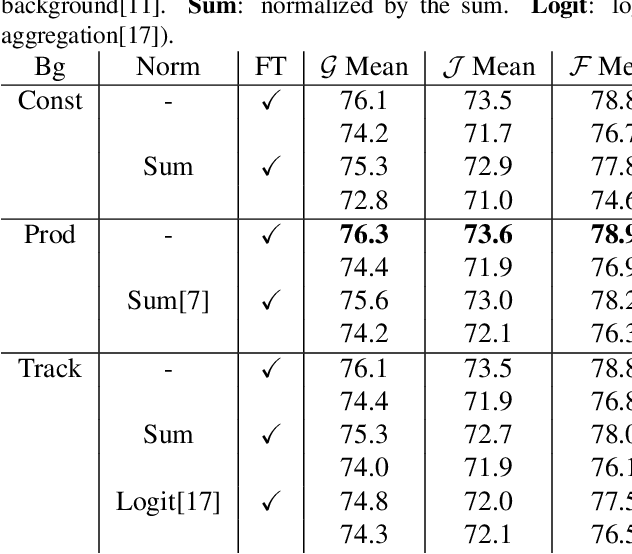
While propagation-based approaches have achieved state-of-the-art performance for video object segmentation, the literature lacks a fair comparison of different methods using the same settings. In this paper, we carry out an empirical study for propagation-based methods. We view these approaches from a unified perspective and conduct detailed ablation study for core methods, input cues, multi-object combination and training strategies. With careful designs, our improved end-to-end memory networks achieve a global mean of 76.1 on DAVIS 2017 val set.